
RiskRank Copilot: Enterprise AI Use-Case Prioritization Platform
A full-stack prioritization platform that replaces ad-hoc AI investment decisions with a transparent, weighted scoring model for ranking enterprise AI use cases and surfacing actionable recommendations for leadership teams.
RiskRank Copilot
A full-stack platform for evaluating, ranking, and recommending enterprise AI use cases using a transparent weighted scoring model.
Overview
Project type: Enterprise AI governance / portfolio prioritization
Role: Product architecture, scoring logic, backend API design, frontend dashboard delivery
Core value: Replaces ad-hoc AI investment decisions with a structured, auditable evaluation workflow
Stack: React 19, FastAPI, SQLAlchemy 2.0, JWT auth, weighted scoring engine
At a glance
- Evaluates AI opportunities across 6 scoring dimensions
- Applies rule-based recommendations, not just numeric ranking
- Supports portfolio-level filtering, rescoring, and dashboard visibility
- Built with 209 automated tests across frontend and backend
- Designed for explainability, auditability, and future extensibility
The Problem
Most organizations want to invest in AI, but few have a disciplined way to decide which ideas deserve funding first.
Common failure modes include:
- Hype-driven prioritization: Projects are selected because they sound impressive, not because they create measurable business value.
- Siloed duplication: Multiple business units pursue overlapping ideas without shared visibility.
- Late governance surprises: Risk, compliance, and data-readiness issues appear after budget and momentum have already been committed.
- Spreadsheet fatigue: Evaluation criteria live in disconnected files with little consistency, auditability, or version control.
CIOs and Heads of AI do not need another slide deck. They need a living system that scores, ranks, and recommends AI opportunities across the portfolio.
The Approach
RiskRank Copilot is a full-stack prioritization platform built around a transparent, configurable scoring engine.
The workflow is structured into four steps:
- Submit: business units propose AI opportunities with structured metadata such as problem statement, expected outcomes, and data sources.
- Score: the engine evaluates each use case across 6 dimensions, including inverted scoring for complexity and risk-related fields.
- Recommend: the system assigns each use case to an actionable recommendation category, not just a number.
- Rank-leadership teams view the portfolio through a dashboard with filtering, traceability, and updated rankings.
Why this design
The system was designed around three practical principles:
- Transparency: stakeholders should understand why a use case ranks where it does
- Actionability: leadership teams need recommendations, not raw scores alone
- Governance-readiness: risk, compliance, and data quality should be evaluated early, not late
Architecture
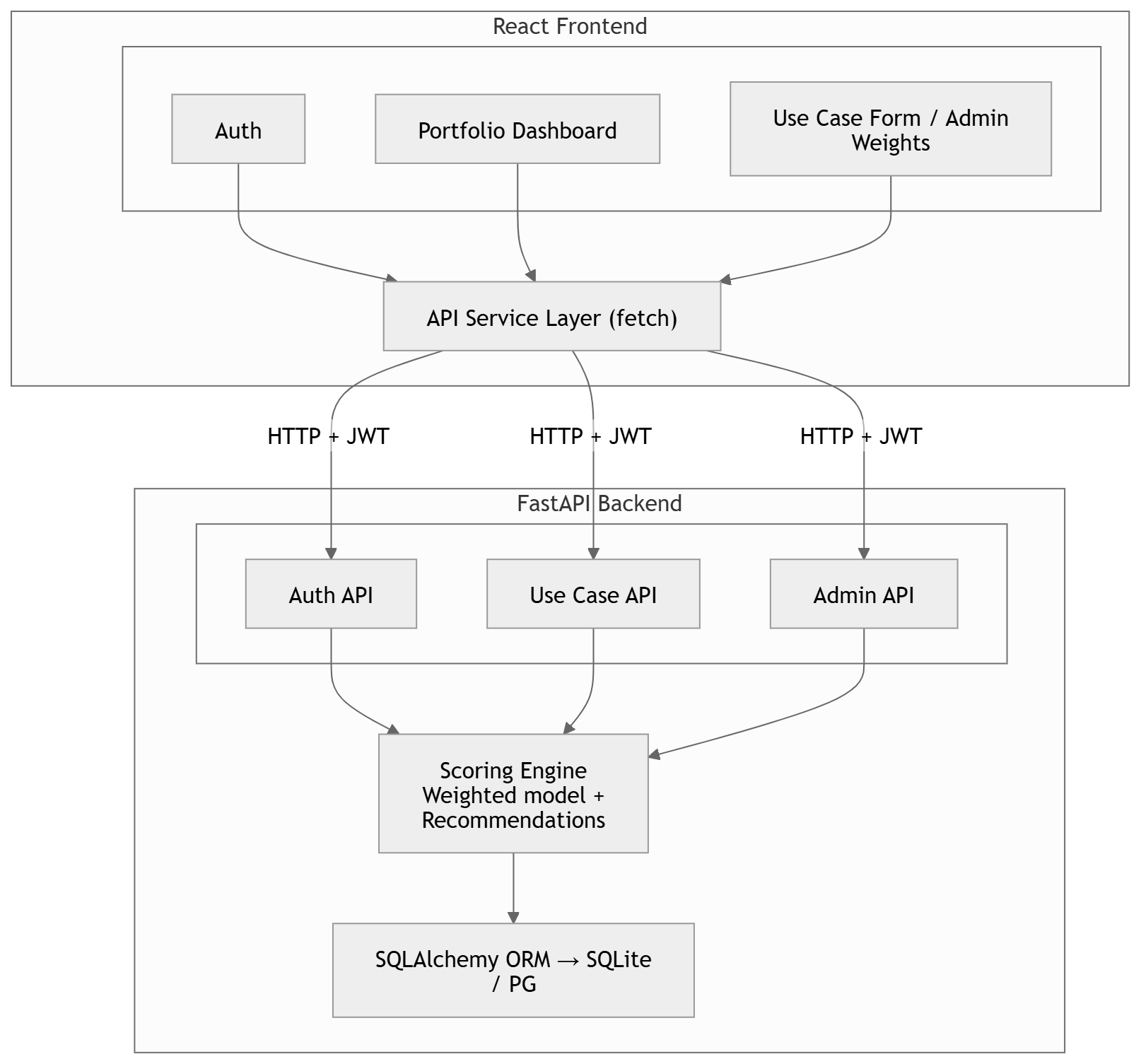
Architecture highlights
- Clear separation between frontend, API, scoring engine, and persistence layer
- Rules-based recommendation logic layered on top of weighted scoring
- Flexible enough to support future additions without breaking core scoring contracts
Key Technical Decisions
1. Weighted scoring instead of ML ranking
A weighted scoring model was chosen over black-box ranking because transparency is essential in enterprise governance.
Stakeholders need to understand why one use case ranks above another. A weighted model is easier to audit, explain, and adjust over time. This is a deliberate constraint that improves trust.
2. Inverted scoring for complexity and risk
A raw score of 5 for implementation complexity means highly complex, which is negative for prioritization.
To keep the input intuitive, the system accepts natural ratings and inverts the value internally using 6 - raw_score for complexity, risk, and compliance-related dimensions. This preserves both usability and scoring correctness.
3. Recommendation categories instead of score-only output
A score alone does not tell leadership what to do next.
The recommendation engine adds action-oriented labels such as Improve Data First or Defer Due to Risk. For example, if data_readiness <= 2, the system always returns Improve Data First, regardless of the overall weighted score.
4. React and FastAPI instead of a monolith
The frontend and backend have different development and deployment profiles.
React with Vite supports fast local iteration and optimized production builds. FastAPI provides async-capable APIs with automatic OpenAPI documentation. The separation also allows either layer to evolve independently.
5. JWT instead of session-based authentication
JWT was selected to support stateless authentication and future API consumption patterns such as integrations, mobile clients, or CLI tools.
The trade-off is token revocation complexity, but for an internal enterprise platform this was acceptable.
Features
Scoring Engine
Each use case is evaluated across 6 configurable dimensions with transparent weights:
| Dimension | Default Weight | Direction |
|---|---|---|
| Business Value | 30% | Higher = better |
| Data Readiness | 20% | Higher = better |
| Technical Feasibility | 15% | Higher = better |
| Implementation Complexity | 10% | Inverted (lower = better) |
| Risk & Compliance | 15% | Inverted (lower = better) |
| Time to Value | 10% | Higher = better |
Recommendation Engine
Each use case receives an actionable classification:
| Recommendation | Trigger |
|---|---|
| Pursue AI Now | Weighted score >= 3.8 and no blockers |
| Use Analytics First | Score 3.0–3.8 with high feasibility |
| Use Rules Automation | Score < 3.0 or moderate feasibility |
| Improve Data First | Data readiness <= 2 (overrides all) |
| Defer Due to Risk | High risk + low business value |
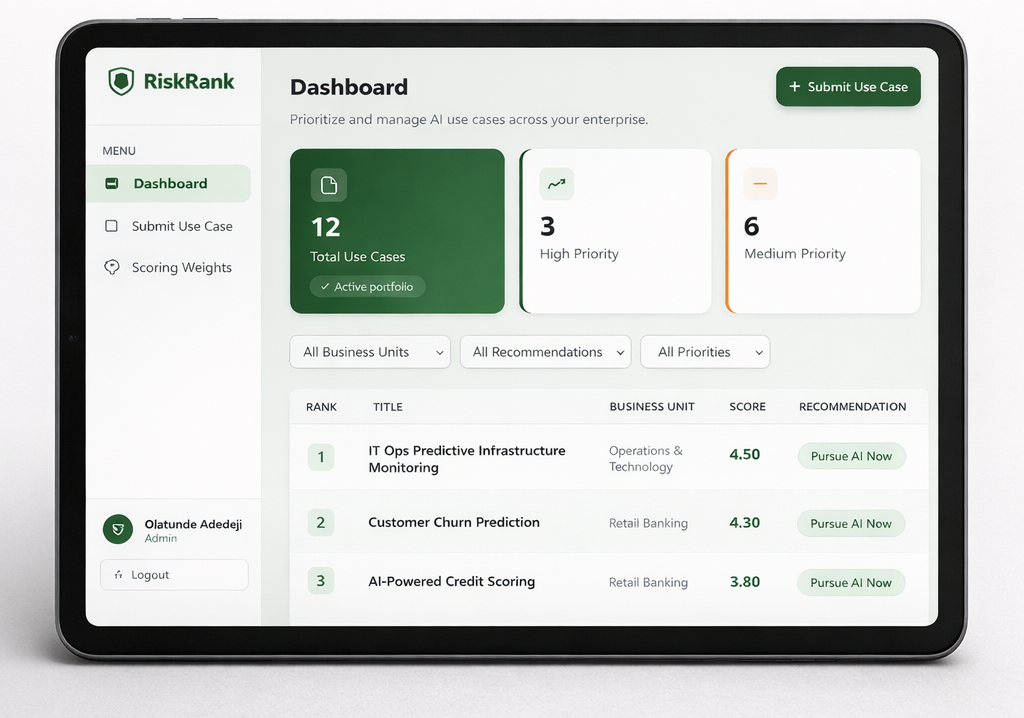
Portfolio Dashboard
- 4-card summary showing total use cases and priority distribution
- Filtering by business unit, recommendation type, and priority band
- Ranked table with weighted score ordering and color-coded priority badges
- SaaS-style dashboard layout for fast executive review
Role-Based Access Control
- Admin: full access, including weight configuration and bulk rescoring
- Analyst: submit and manage owned use cases
- Viewer: read-only access to the dashboard
Admin Weight Configuration
Admins can update scoring weights from a dedicated panel. Saving new weights automatically triggers a portfolio-wide rescore.
Validation is enforced on both client and server, and total weights must equal 1.00.
Tech Stack
| Layer | Technology |
|---|---|
| Frontend | React 19, React Router v6, Vite |
| Backend | FastAPI, SQLAlchemy 2.0, Pydantic v2 |
| Auth | JWT (python-jose + passlib/bcrypt) |
| Database | SQLite (dev) / PostgreSQL (prod) |
| Testing | pytest (130 tests) + Vitest (79 tests) = 209 tests |
| Containerization | Docker + Docker Compose |
Testing Strategy
The codebase includes 209 automated tests across backend and frontend.
Backend
- API integration tests (60): CRUD flows, RBAC, filters, dashboard stats, weight configuration, and data integrity
- Scoring engine tests (35): weighted calculations, inverted dimensions, recommendation paths, priority bands, and rationale generation
- Auth tests (13): password hashing, JWT handling, and token validation scenarios
- Schema validation tests (22): boundary cases, field constraints, and optional input handling
Frontend
- Component tests: LoginPage, DashboardPage, UseCaseFormPage, AdminWeightsPage
- Routing tests: protected routes, redirects, and unknown route handling
- API client tests: request formatting, error handling, and auth header injection
- Context tests: AuthContext state handling and localStorage persistence
Test design note
Per-test isolation is enforced: the backend recreates schema state per test, and the frontend clears local storage between runs.
Dataset
The seed data models a financial services group with 6 business units:
- Retail Banking
- Wealth Management
- Insurance
- Capital Markets
- Risk & Compliance
- Operations & Technology
It includes 12 pre-scored AI use cases spanning fraud detection, credit scoring, document analysis, and predictive infrastructure monitoring.
Results & Takeaways
Key outcomes
- Built a transparent scoring workflow for enterprise AI portfolio decisions
- Added rule-based recommendations to make rankings more actionable
- Enforced governance logic earlier in the decision process
- Established a reusable architecture for future scaling and integration
Technical takeaways
- The scoring engine handled edge cases reliably, including all-max, all-min, and inverted-dimension scenarios
- The
data readinessoverride captured a common real-world constraint: weak data should block premature AI investment - RBAC coverage reduced privilege-escalation risk and protected admin-only controls
- The architecture supports future upgrades such as PostgreSQL, Redis, and LLM-based rationale generation without changing core API contracts
Try It
The source is on GitHub.
# Backend
cd backend && python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt && python seed.py
uvicorn app.main:app --reload
# Frontend
cd frontend && npm install && npm run dev
Open http://localhost:5173 and sign in with admin@ola.ai / admin123