
EviVault Assistant: RAG-Powered Enterprise Document Intelligence Platform
A full-stack RAG platform that transforms organizational policy documents into an intelligent assistant, delivering citation-backed answers grounded in enterprise knowledge.
EviVault Assistant
A full-stack document intelligence platform that turns internal policy documents into a citation-backed assistant for trusted enterprise question answering.
Overview
Project type: Enterprise document intelligence / retrieval-augmented generation
Role: Product architecture, ingestion workflow design, RAG pipeline implementation, backend API design, frontend delivery
Core value: Replaces fragmented document search with grounded answers backed by verifiable evidence
Stack: React 19, FastAPI, ChromaDB, SentenceTransformers, JWT auth, RAG pipeline
At a glance
- Ingests PDF, DOCX, TXT, and Markdown documents
- Uses semantic retrieval over chunked internal content
- Returns citation-backed answers with evidence metadata
- Abstains when retrieval quality is too weak
- Supports local embeddings and no-LLM fallback for constrained environments
- Designed for trust, auditability, and upgradeable enterprise deployment
The Problem
Organizations accumulate large volumes of internal knowledge: onboarding guides, infrastructure policies, compliance rules, safety documents, and operational procedures.
The problem is rarely knowledge creation. It is knowledge access.
Common failure modes include:
- Search fatigue: employees search shared drives, skim long PDFs, and still leave unsure whether they found the right answer
- Tribal knowledge dependency: critical answers live with a small number of experienced people, creating delays and operational risk
- Hallucination risk: off-the-shelf LLM tools can produce plausible answers that are not grounded in actual company policy
- No audit trail: traditional internal Q&A workflows rarely show which exact document passage supports the answer
For policy, safety, and compliance-heavy environments, “probably correct” is not good enough. Teams need answers they can verify.
The Approach
EviVault Assistant is a retrieval-augmented document intelligence platform built around a strict principle:
Every answer should be backed by evidence. If the evidence is weak, the system should abstain.
The workflow follows four stages:
- Upload- users add internal documents in PDF, DOCX, TXT, or Markdown format
- Ingest- the pipeline extracts text, chunks content into overlapping segments, generates embeddings, and stores them in a vector database
- Retrieve- user questions trigger semantic search over the indexed chunks
- Answer- the system returns a grounded answer with citations, confidence metadata, and source excerpts
Why this design
The platform was designed around three practical goals:
- Grounding: answers must come from retrieved internal evidence, not model guesswork
- Auditability: users should be able to inspect the source passage behind each response
- Graceful failure: when retrieval is weak, the system should refuse rather than hallucinate
Architecture
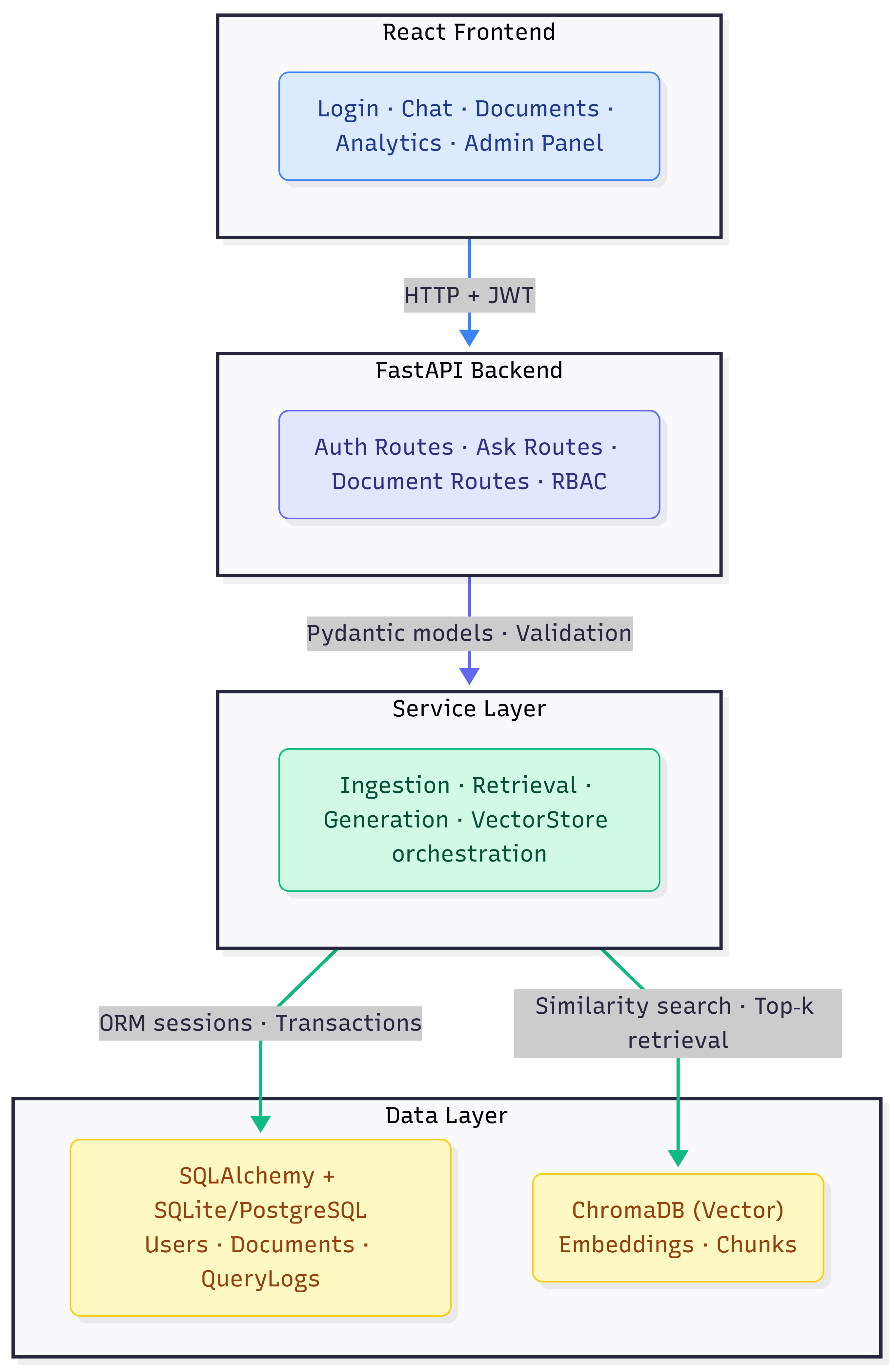
Architecture highlights
- Clear separation between ingestion, retrieval, generation, and persistence layers
- Grounding metadata carried from retrieval into the answering interface
- Optional generation layer with extractive fallback for environments without external LLM access
- Vector store abstraction designed for future backend swaps without breaking the application contract
Key Technical Decisions
1. RAG over fine-tuning
RAG was chosen over fine-tuning because document-backed enterprise Q&A needs traceability.
Fine-tuning stores knowledge in model weights, making updates slower and answer provenance harder to inspect. RAG keeps knowledge in the document layer, allowing answers to reference specific retrieved chunks. For internal policy and compliance use cases, that traceability is more important than stylistic fluency.
2. Similarity threshold for abstention
Large language models will generate an answer even when retrieval quality is poor.
To prevent confident but ungrounded responses, the system applies a retrieval quality gate. If no retrieved chunk exceeds a cosine similarity threshold of 0.35, the platform abstains rather than answering. This is a deliberate product decision: in high-trust settings, no answer is safer than a fabricated one.
3. Local embeddings with all-MiniLM-L6-v2
The embedding model was selected as a pragmatic local-first option.
all-MiniLM-L6-v2 provides strong semantic retrieval quality with lightweight CPU-friendly inference and no mandatory API dependency. This makes the platform more suitable for internal deployments where document content should remain within the organization boundary.
4. ChromaDB for embedded vector search
ChromaDB was chosen because it keeps the vector layer simple and self-contained.
It runs locally, persists to disk, and avoids additional infrastructure for early-stage internal deployments. The platform also uses a vector store abstraction, so migration to a managed service later can be done with limited code changes.
5. Extractive fallback when no LLM is configured
Not every deployment can depend on an external generation API.
When no OpenAI key is configured, the platform falls back to extractive summarization by returning the most relevant chunk instead of generating a synthesized response. This allows the system to degrade gracefully, support local development, and remain useful in restricted environments.
6. JWT for stateless authentication
JWT was selected to support stateless authentication and future multi-client access patterns such as APIs, CLI tools, or additional frontends.
The trade-off is more complex token revocation, but for the current architecture that trade-off is acceptable.
Features
RAG Pipeline
The core pipeline is organized into four stages:
| Stage | Implementation | Detail |
|---|---|---|
| Extract | pypdf, python-docx, plain text | Supports PDF, DOCX, TXT, MD |
| Chunk | 512-char windows, 64-char overlap | Overlap improves retrieval continuity |
| Embed | SentenceTransformers (all-MiniLM-L6-v2) | 384-dim vectors with local inference |
| Retrieve | ChromaDB cosine similarity, top-5 | Scoped by user access and document status |
Confidence & Grounding
Every answer includes structured evidence signals:
| Signal | Meaning |
|---|---|
| Confidence: High | Top chunk similarity > 0.6 |
| Confidence: Medium | Top chunk similarity > 0.4 |
| Confidence: Low | Top chunk similarity > 0.35 |
| Abstention | No chunk exceeds 0.35, so the system refuses |
| Grounded: true/false | Whether the response is supported by retrieved text |
Evidence Panel
Each answer surfaces:
- filename
- chunk index
- similarity score
- retrieved excerpt
This creates an auditable chain from question to evidence, helping users verify not only the answer, but the reasoning basis behind it.
Document Management
- Upload PDF, DOCX, TXT, and MD documents
- Automated extract → chunk → embed → store pipeline
- Processing status tracking: processing, ready, failed
- Per-user document scoping
- Visible chunk counts and metadata per document
Role-Based Access Control
- Admin: full access, including user management
- Researcher: upload documents, ask questions, and view analytics
- User: ask questions against available documents
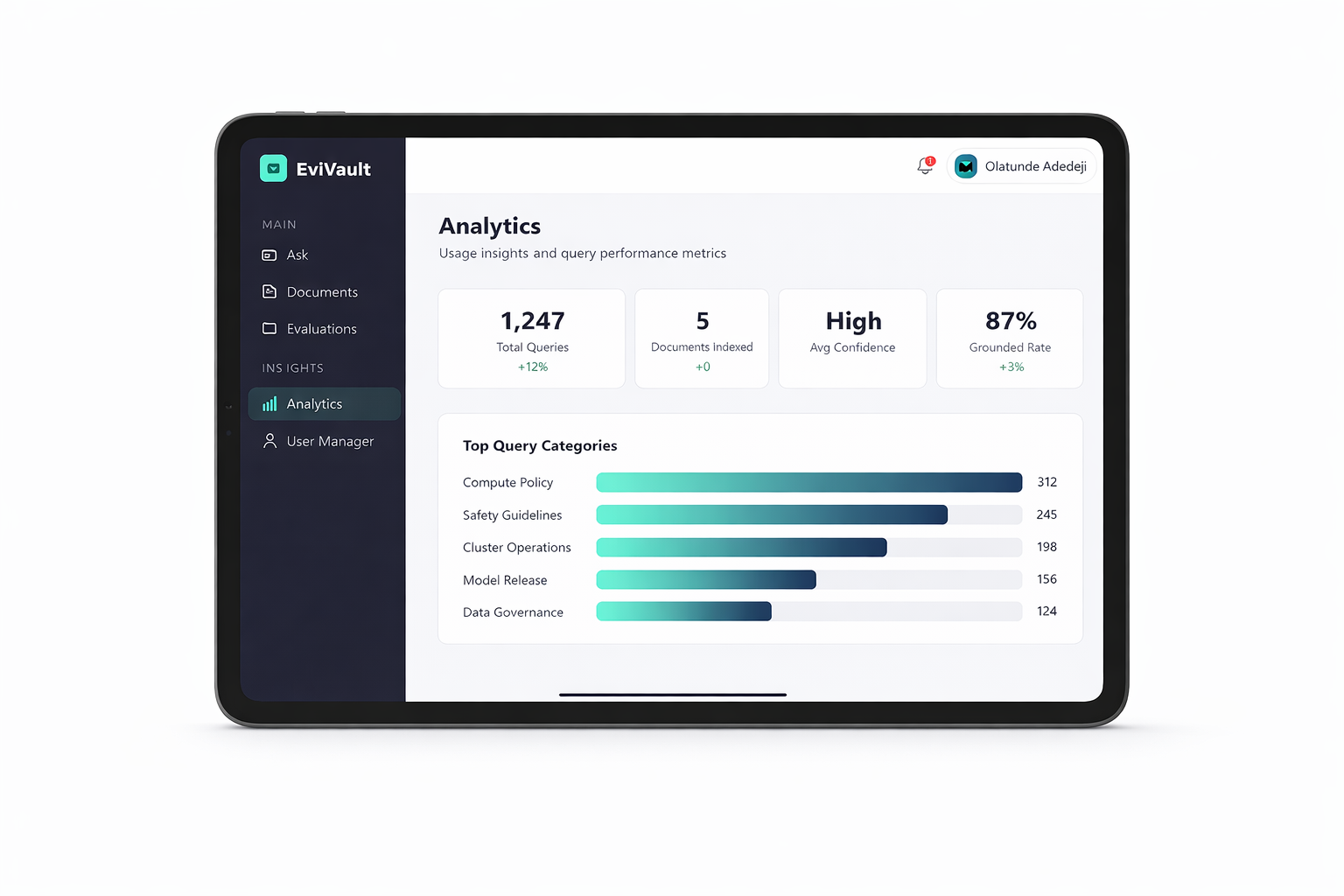
Admin Dashboard
- User CRUD management
- Usage analytics and query categories
- Evaluation metrics for monitoring retrieval and answering behavior
Tech Stack
| Layer | Technology |
|---|---|
| Frontend | React 19, React Router v6, Vite |
| Backend | FastAPI, SQLAlchemy 2.0, Pydantic v2 |
| Vector DB | ChromaDB 0.5.11 |
| Embeddings | SentenceTransformers (all-MiniLM-L6-v2) |
| LLM | OpenAI API (optional, with extractive fallback) |
| Auth | JWT (python-jose + passlib/bcrypt) |
| Database | SQLite (dev) / PostgreSQL 16 (prod) |
| Document Parsing | pypdf 5.0.1, python-docx 1.1.2 |
| Testing | pytest + httpx |
| Containerization | Docker + Docker Compose |
Data Model
The data model supports the full lifecycle from upload to grounded response:
| Entity | Key Fields | Relationship |
|---|---|---|
| User | UUID, email, role, hashed password | Has many Documents, has many QueryLogs |
| Document | Filename, MIME type, chunk count, processing status | Belongs to User, has many Chunks |
| DocumentChunk | Content slice, offsets, vector reference ID | Belongs to Document |
| QueryLog | Question, answer, grounded flag, confidence, retrieved chunk count | Belongs to User |
Dataset
The seed script models an AI research lab with 5 internal policy documents:
- AI Research Lab Handbook
- AI Safety Guidelines
- GPU Cluster Usage Policy
- Model Release Checklist
- Onboarding Guide
Three seeded users; one admin and two researchers, allow immediate testing of upload, retrieval, and grounded Q&A flows.
Results & Takeaways
Key outcomes
- Built a citation-first enterprise Q&A workflow grounded in internal documents
- Reduced dependence on keyword search and undocumented tribal knowledge
- Added abstention logic to reduce ungrounded answering risk
- Created an architecture that supports secure internal deployment and future retrieval upgrades
Technical takeaways
- Grounded answers increase trust because users can inspect the exact evidence passage
- Similarity-gated abstention is a product feature, not a system weakness
- Local embeddings make the platform more viable for private and air-gapped environments
- The architecture supports clear future upgrades such as reranking, async ingestion, managed vector databases, and query history visualization
Try It
The source is on GitHub.
# Backend
cd backend && python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt && python seed.py
uvicorn app.main:app --reload --port 8000
# Frontend
cd frontend && npm install && npm run dev
Open http://localhost:5173 researcher@ola.ai / admin123